## Introduction
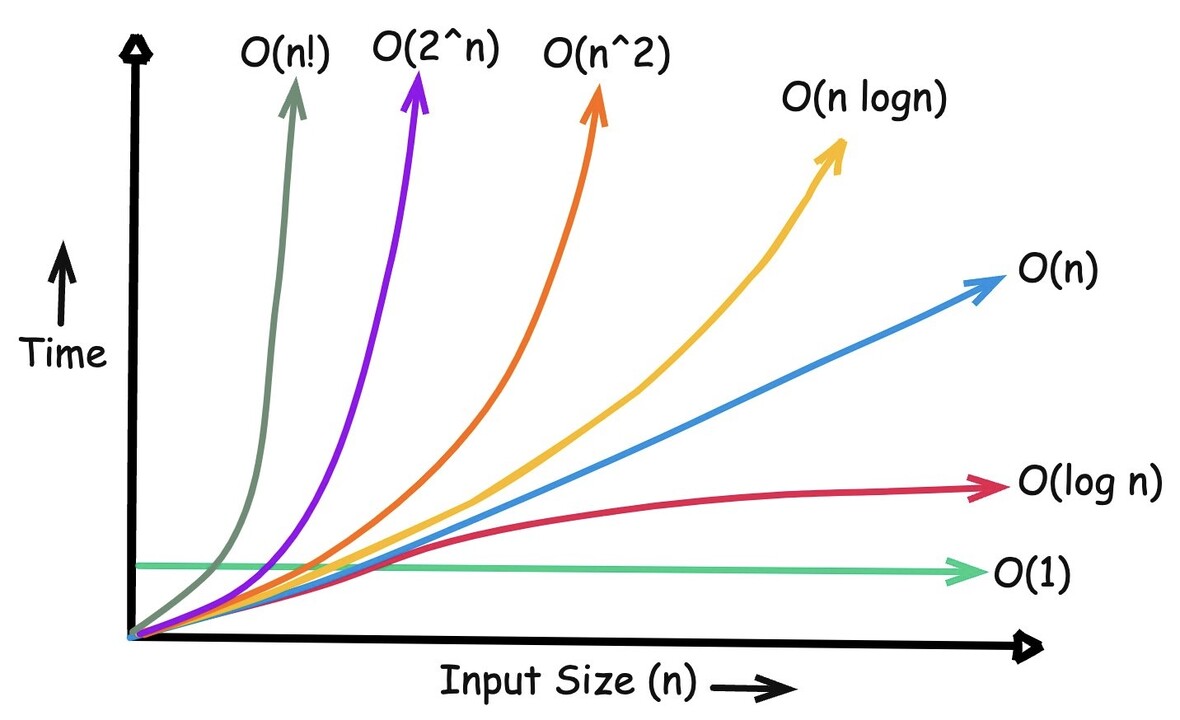
The O(n) notation in data structures describes the worst-case complexity of an algorithm, analyzing how its performance (execution time or memory usage) scales with the size of the input data, denoted by "n".
Array
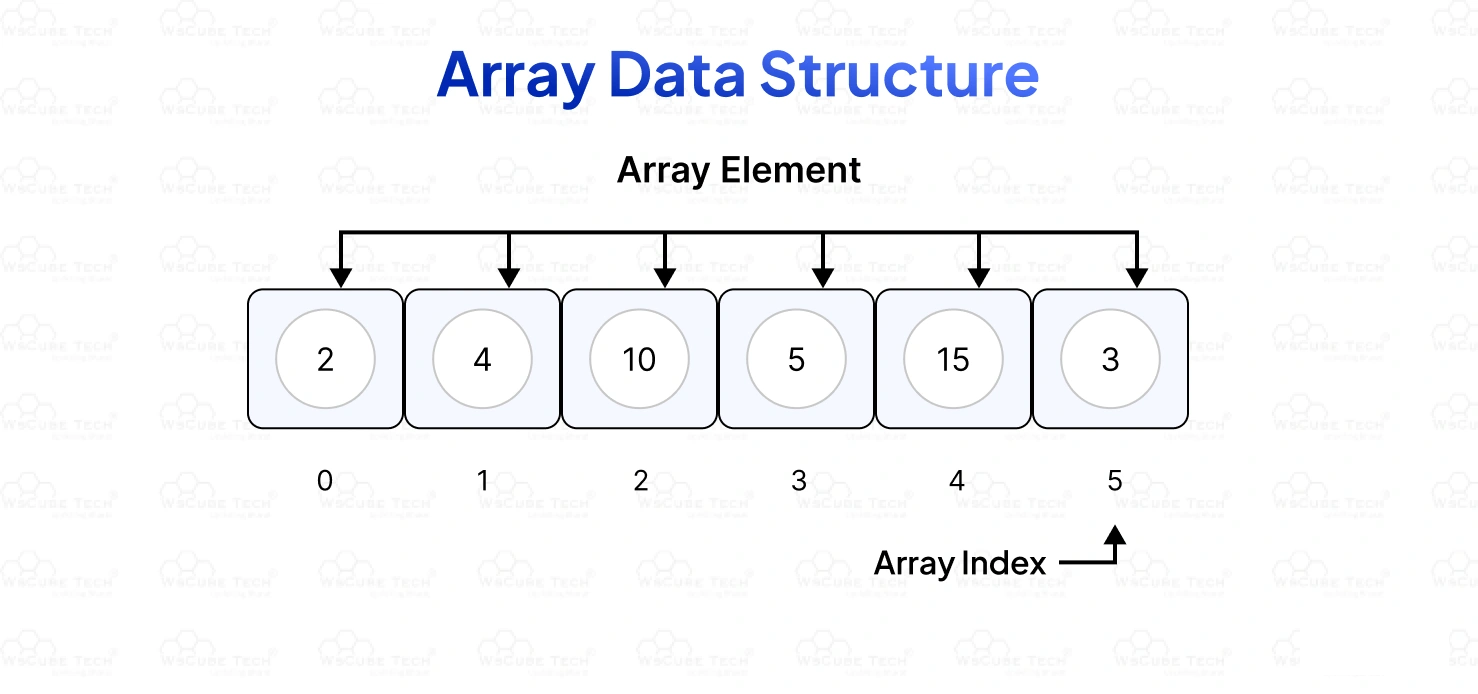
Description Arrays are collections of elements stored in contiguous computer memory; a selected element can be accessed using a numerical index. Each element occupies the same amount of memory, allowing for simple data access at a selected index (memory start + (index * size of a single element)).
Advantages
- Constant time data access regardless of array size
- Very fast retrieval of the entire array into the processor cache
- Occupies little memory compared to other data structures
- Simple and intuitive data indexing
Disadvantages
- Static data structure requires allocating new memory blocks when adding more data, and then copying them
- Demanding data addition or deletion operations
- Memory allocation must be contiguous
Operations
- Adding: adding to the end O(1), inserting in the middle O(n)
- Deleting: deleting from a selected position O(n)
- Searching: access by index O(1), searching for value O(n)
Linked list
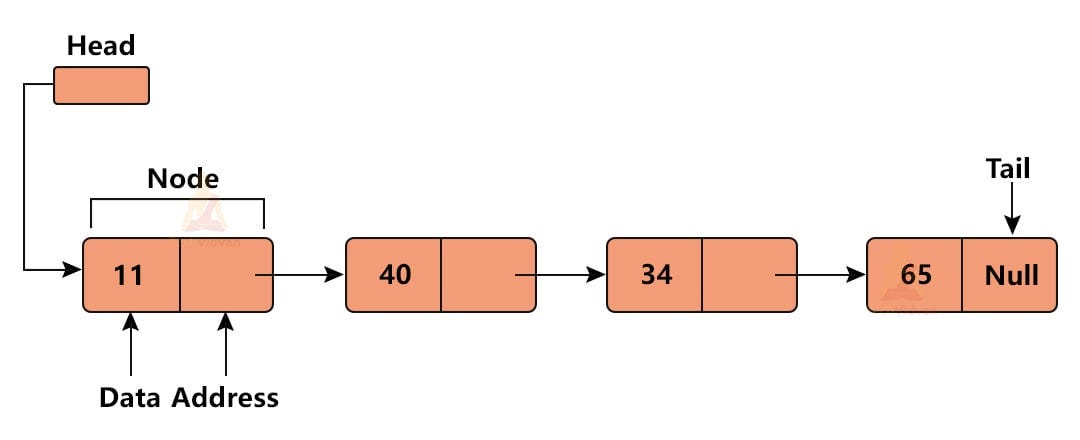
Description A linked list consists of nodes containing data and a pointer to the next element (sometimes also to the previous one - doubly linked list). Elements are stored in various, scattered memory locations, linked only by memory references, creating a sequential data chain without the need to reserve a large memory block.
Advantages
- Dynamic addition of new elements with efficient memory utilization
- Constant time for adding and deleting elements at a known memory location
- Does not require pre-allocation of a larger memory area
- Easy organization by re-pointing pointers
Disadvantages
- Must traverse all preceding elements to find the desired object
- Retrieving data into the cache takes a long time due to scattered memory addresses
- A single object occupies more memory
Operations
- Adding: adding at a known position O(1), adding at another position O(n)
- Deleting: deleting from a known position O(1), deleting from another position O(n)
- Searching: searching for a value O(n), accessing a selected position O(n)
Hash table
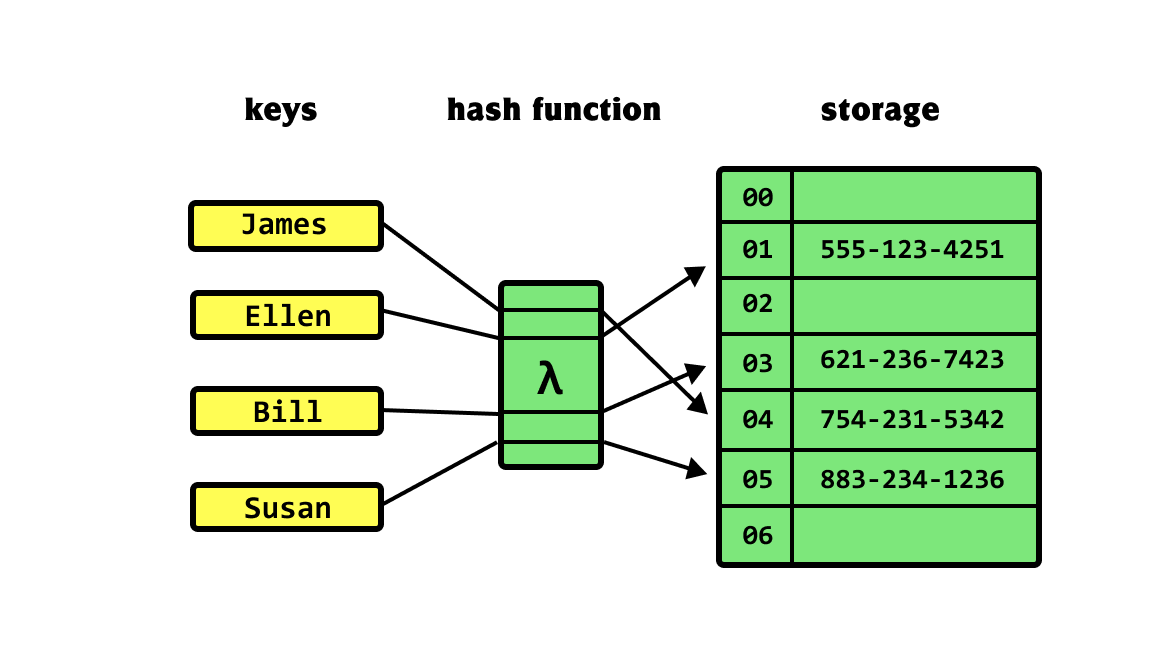
Description This is a special type of array where the key can be any data type: number, text, object. It uses a hashing function to calculate the index in the array, which allows for very fast access to the value associated with the given key. A good hashing function is very important, as it will help prevent conflicts between keys. Modern implementations (like Python dict or Java HashMap) have very good hashing functions and collision resolution techniques, making the worst-case O(n) very rare in practice.
Advantages
- Constant time for addition, deletion, and value searching operations
- Flexible key types allow for complex data relationships
- Excellent for implementing cache and databases
- Natural mapping of keys and values, no need to use meaningless numbers as keys
Disadvantages
- Frequent key collisions can lead to worse performance of operations (O(1) -> O(n))
- Occupies a lot of memory
- Performance depends heavily on the hashing function
Operations
- Adding: average case O(1), worst case O(n)
- Deleting: average case O(1), worst case O(n)
- Searching: average case O(1), worst case O(n)
Set
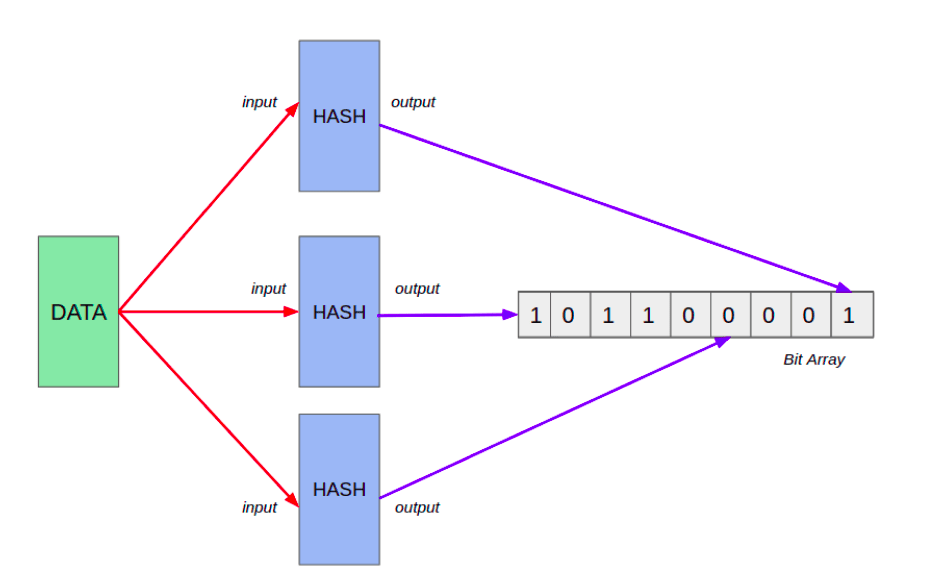
Description Sets are collections that enforce data uniqueness by storing each value at most once. Typically implemented using hash tables or balanced trees, they provide efficient checking for value existence and mathematical operations.
Advantages
- Automatic data uniqueness guarantee
- Very fast checking for value existence
- Performing fast mathematical operations (unions, differences, intersections)
Disadvantages
- No indexing or positional access
- Occupies more space than regular arrays
- Difficult to implement efficiently to ensure uniqueness
Operations
- Adding: adding an element for sets implemented on hash tables O(1), and for trees O(log(n))
- Deleting: deleting an element for sets implemented on hash tables O(1), and for trees O(log(n))
- Searching: searching for an element for sets implemented on hash tables O(1), and for trees O(log(n))
Stack
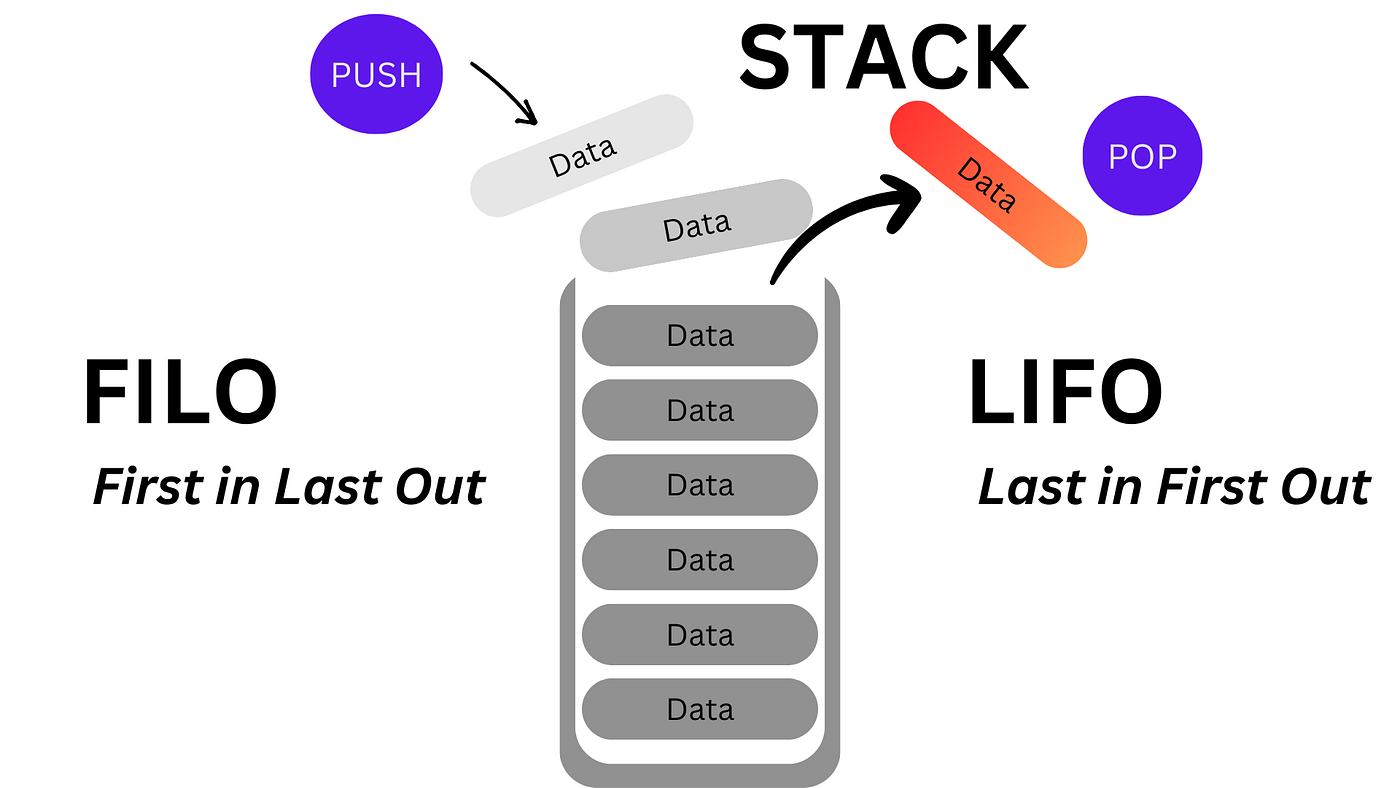
Description A stack is an abstract data structure implementing the FILO (First In - Last Out) access style. It is not a separate data structure in itself, like arrays or linked lists, but merely uses various implementations to provide different data access. Elements are added and removed from the same side, known as the "top of the stack". You can imagine it like stacking books, to get to the bottom, you must first remove all the books from the top.
Advantages
- Simple and predictable data access
- Efficient implementation using arrays
- Natural use in recursive algorithms
Disadvantages
- Very restrictive data access
- To find a value further down, you must first remove the data above it
- Each search operation requires creating a new stack
- Not suitable for problems requiring random access to data
Operations
- Adding: adding to the top O(1)
- Deleting: deleting from the top O(1)
- Searching: checking the top element O(1), searching for a specific value O(n)
Queue
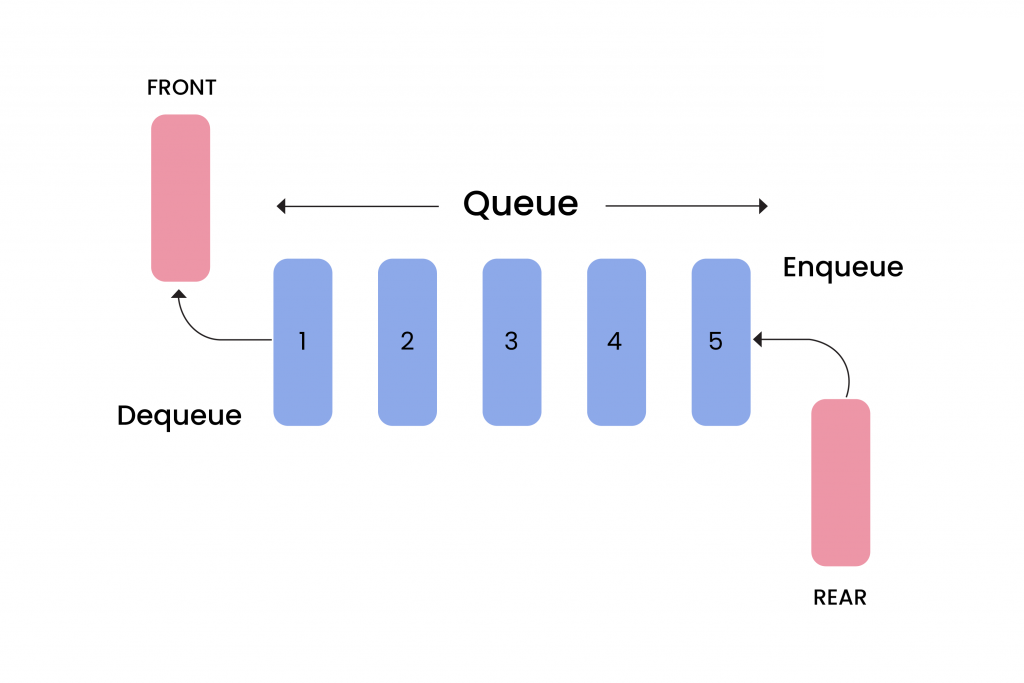
Description Similar to a stack, a queue is also an abstract data structure, but it implements the FIFO (First In - First Out) access style. Elements are added to the back and removed from the front, ensuring fair data processing in the order they were added. An efficient implementation can be achieved using a circular buffer or a doubly linked list.
Advantages
- Processes data exactly in the order it was added
- Ideal for modeling real-world waiting systems
- Excellent for breadth-first traversal algorithms and level-order processing
Disadvantages
- Requires efficient implementation (circular buffer) to avoid O(n) complexity operations when removing from the front of a regular array
- More complex than a stack, requiring 2-directional access
- Limited access to internal data
Operations
- Adding: adding elements from the back O(1) with correct implementation
- Deleting: deleting elements from the front O(1) with correct implementation
- Searching: checking the first element O(1), searching for a specific value O(n)
Trees
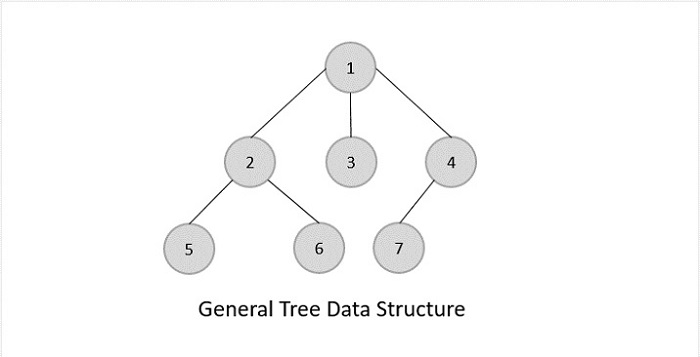
Description Trees are hierarchical data structures containing nodes connected by edges, with always only 1 connection from one node to another. A tree always starts with a single element, called the "root"; in the case of regular trees, each node can have zero or many child nodes, forming parent-child relationships between nodes. Popular self-balancing implementations include AVL and Red-Black trees.
Advantages
- Natural representation of hierarchical structures
- Efficient searching and sorting in the case of balanced trees
- Recursive algorithms naturally map tree structures
- Flexible organization supporting various ways of data access
Disadvantages
- More complex implementation than linear data structures
- Performance heavily depends on tree balancing
- Recursive operations can cause program stack overflow
- Requires very careful balancing to maintain optimal operations
Operations
- Adding: adding a node in the case of a balanced tree O(log(n)), in the worst case O(n)
- Deleting: deleting a node in the case of a balanced tree O(log(n)), in the worst case O(n)
- Searching: searching for a value in the case of a balanced tree O(log(n)), in the worst case O(n)
Graph
Description Graphs are collections of vertices connected by edges representing relationships between values. They can be unidirectional or bidirectional, weighted or unweighted, or cyclic, making them the most diverse among data structures. The complexity of operations heavily depends on the representation method - the following refer to representation using an adjacency list.
Advantages
- The most diverse data structure for modeling complex relationships
- Natural representation of networks, dependencies, and connections
Disadvantages
- The most complex data structure to implement and maintain
- Algorithms often characterized by high computational complexity
- Memory-intensive, especially for dense connections
- Detecting and managing cycles increases complexity
Operations
- Adding: adding a vertex O(1), adding an edge O(1)
- Deleting: deleting a vertex O(V + E) (where V - number of vertices, E - number of edges), deleting an edge O(E)
- Searching: searching for a vertex O(V), path between vertices along edges O(V + E)
Summary
| Structure | Description | Applications | Biggest advantage | Biggest disadvantage | Adding | Deleting | Searching |
|---|---|---|---|---|---|---|---|
| Array | Elements in contiguous memory with index access | Data buffers, mathematical matrices | Constant access time O(1) | Static size, costly insertion | O(1) | O(n) | O(1) |
| Linked list | Nodes connected by pointers | Stack/queue implementation, text editors | Dynamic size | No index access | O(1) | O(1) | O(n) |
| Hash table | Key-value mapping via hash function | Databases, cache, dictionaries | Very fast access by key | Collisions can degrade performance | O(1) | O(1) | O(1) |
| Set | Collection of unique elements | Mathematical operations, deduplication | Automatic uniqueness | No positional access | O(1) | O(1) | O(1) |
| Stack | LIFO - last in, first out | Function calls, expression parsing | Simplicity of implementation | Very limited access | O(1) | O(1) | O(n) |
| Queue | FIFO - first in, first out | Queueing systems, BFS algorithms | Fair processing | Implementation complexity | O(1) | O(1) | O(n) |
| Tree | Hierarchical structure with a root | File systems, decision trees | Efficient searching in the structure | Requires balancing | O(log n) | O(log n) | O(log n) |
| Graph | Vertices connected by edges | Social networks, maps, routing | Models complex relationships | Very complex implementation | O(1) | O(V+E) | O(V+E) |